Software evolves - An experience guided by results
Systems, languages, and applications come and go as people progress in their own careers, problems that had not so obvious solutions in the beginning, become easier to tackle as application and team evolves. In this post, I would like to share a bit about my experience on migrating and scaling a system that I worked with, by observing and trying to understand the problem before thinking about changing the technology completely.
There are multiple factors that influences the team to use a language, it can go through speed constraints, team familiarity to the language or how fast people expect things to be done. However I believe no language is perfect, no language will allow you and your team to scale 10, 20, 100 times because no language does that but software architecture does. Software changes, sometimes completely. Its like writing a post or a book sometimes you start with a small idea and in the end one might end with something completely different. So as you might imagine its quite hard to get everything right from the beginning.
While working at Delivery Hero, I had the opportunity to work in a team that was reponsible for migrating the system to a new one. At that point, it was decided to keep the same language but avoiding obvious bottlenecks.
One of multiple problems, that prevented the initial solution from scaling nicely, was a loop that checks every single delivery and rider applying or not actions based on configurations the app allows.
Unfortunately I cannot share the exact same code, but I created something that represents the problem pretty well. Along the this post I will try to guide you through the same process the team went through talking about the past, present and what was my idea about the future.
The past
Imagine you are building a software that keeps track of a mobile device’s position. As goal, the application has to keep track of a state, and after a certain period it should check a bunch of rules to take or not actions based on the state.
To handle that, the initial solution loops through a list of devices checking if the latest location was received recently and if it doesnt the app changes the device status to out_of_range. Besides that in case the device is already out_of_range for two periods in a row it marks the device as offline.
filter_online.each do |person|
device.move_to('offline') if device.is?('out_of_range')
device.move_to('out_of_range') if device.no_location_received?
endThe code above is just a small part of the solution, for the full version please take a look here
By executing the function above every minute the problem is solved, right?
Hold on, what if each check takes one second? As you might notice, we have a O(N) here and according to Rob Bell
“O(N) describes an algorithm whose performance will grow linearly and in direct proportion to the size of the input data set.”
Taking that into consideration, once the app have 61 devices it no longer able to run the solution in one minute and our solution will be invalid. Furthermore, based on my experience I can enumerate a few others issues like:
- If a single device returns an error or the app crashes, the devices which were not checked yet will have wait until the next period to be processed;
- Given that the solution sequential, its impossible to distribuite the load across different instances, pods or threads;
- The interval & number of checks applied to each device might become quite inconsistent, if the interval decreases considerably from 1 minute to 30 seconds for example;
I might be missing others but I think the idea its pretty clear here, it doesnt scale because we cannot divide and conquer, its quite fragile and error prone. How can we make it better?
The present
One of the things I’ve been experimenting along these years is Elixir. From a Ruby developer perspective, the language is quite familiar and it has the awesome and battleproven OTP providing great actor model system based on GenServer. However as with every technology, it takes time and a huge effort for companies and people to start considering it. Well, as Ruby and Rails was already familiar for most of the team members and the risk had to be minimized, the second version was written in Ruby using Rails as web framework. Giving us a quite mature solution that offers also stable foundation for 90% of the web related problems. So how was it implemented?
The problems with the initial solution are scaling and making each check independent from each other. So what if each device could be checked individually with its own “process”, not affecting any others without changing the language? That would be pretty cool, right?
The proposed solution would look like a recursive call using Sidekiq to treat errors, something like the following
class CheckWorker
include Sidekiq::Worker
def perform(index)
device = DEVICES[index]
Sidekiq.logger.info(device)
if device.is?('out_of_range')
return device.move_to('offline')
end
device.move_to('out_of_range') if device.no_location_received?
CheckWorker.perform_in(10, index)
end
end
DEVICES.each_with_index do |_device, index|
CheckWorker.perform_in(10, index)
endFor the full version please take a look here
Lets now go back to the problems we had initially to validate if new solution is better or worse.
About the first problem, now the execution time is only O(1) per job since now each device is managed by its own job individually. Of course it also adds some overhead for each job, but it can no longer affect any other device or even stop the process, so thats a win. Now jobs go to redis and can easily distributed across nodes, besides that Kubernetes HPA can be used to increase the number of pods, as the number of jobs increases, by checking cpu levels, cool right? The service we rewrote this approach pretty much everywhere within its core.
Based on the experience I had writing this app, I can tell you that the solution above scales pretty well, after adopting the Sidekiq Pro and it’s reliable_scheduler it got even better. Features that were impossible before like decreasing intervals to 10 seconds or even customising the processing flow, started becoming quite easy and straightforward. The company grew a lot, it went from 800 thousand orders daily to something like 5 or 6 million, in our biggest country we have the following numbers:
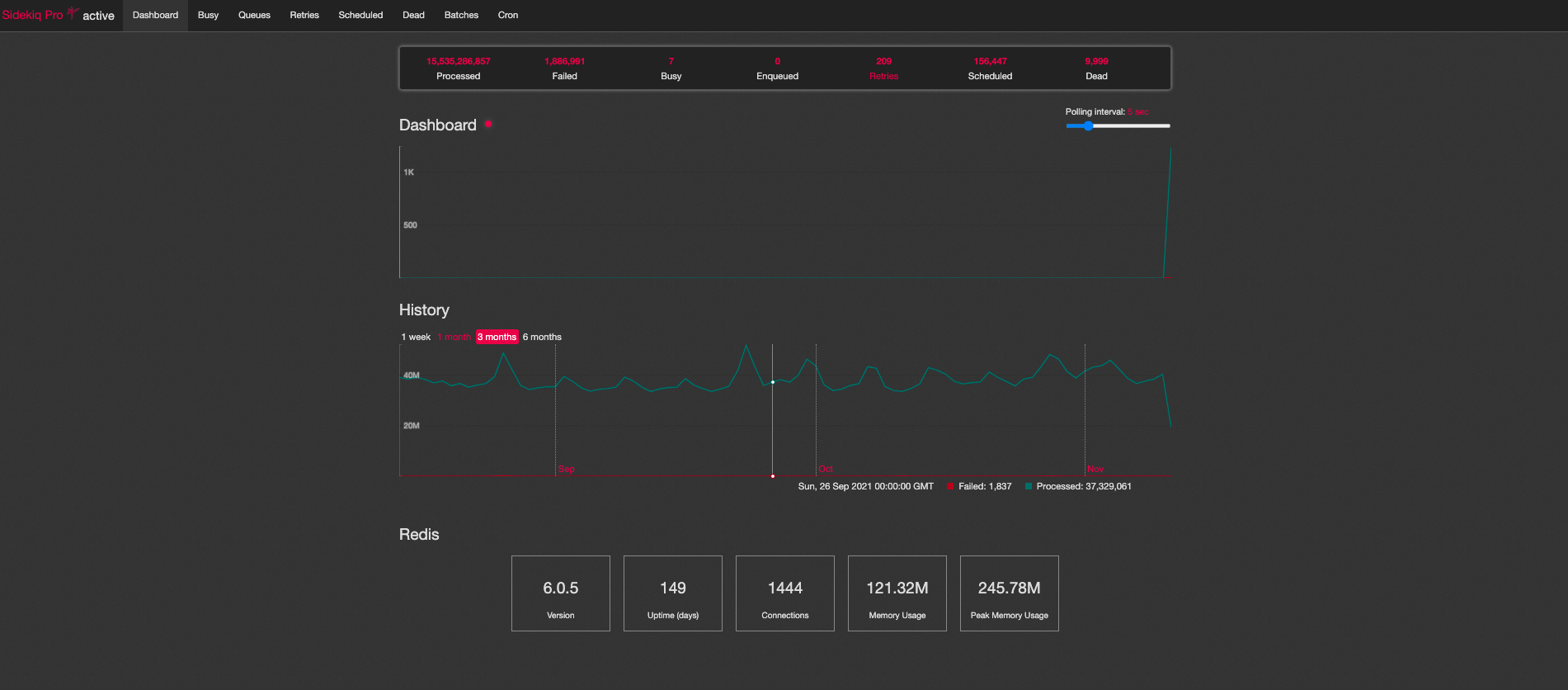 40 million jobs every day in a single country not too shabby
40 million jobs every day in a single country not too shabby
Even though the current approach scales pretty well, it doesnt scale infinitely, at least not in the way we have right now. As you might know Postgres has a limit in number of connections and with that as we add more and more pods to handle the increasing number of jobs at some point it will be just unbearable to the DB.

Wait, there is a way to solve that, the solution we found was using PGBouncer in transaction mode, so each query to the DB executes quite fast creating like a ConnectionPool for all the pods.
Cool, all problems solved right? Temporarely, this solution scales until a certain point due to DB constraints, at some point if for some reason any slow query is introduced or too many things are executed in parallel we noticed the following behaviour.
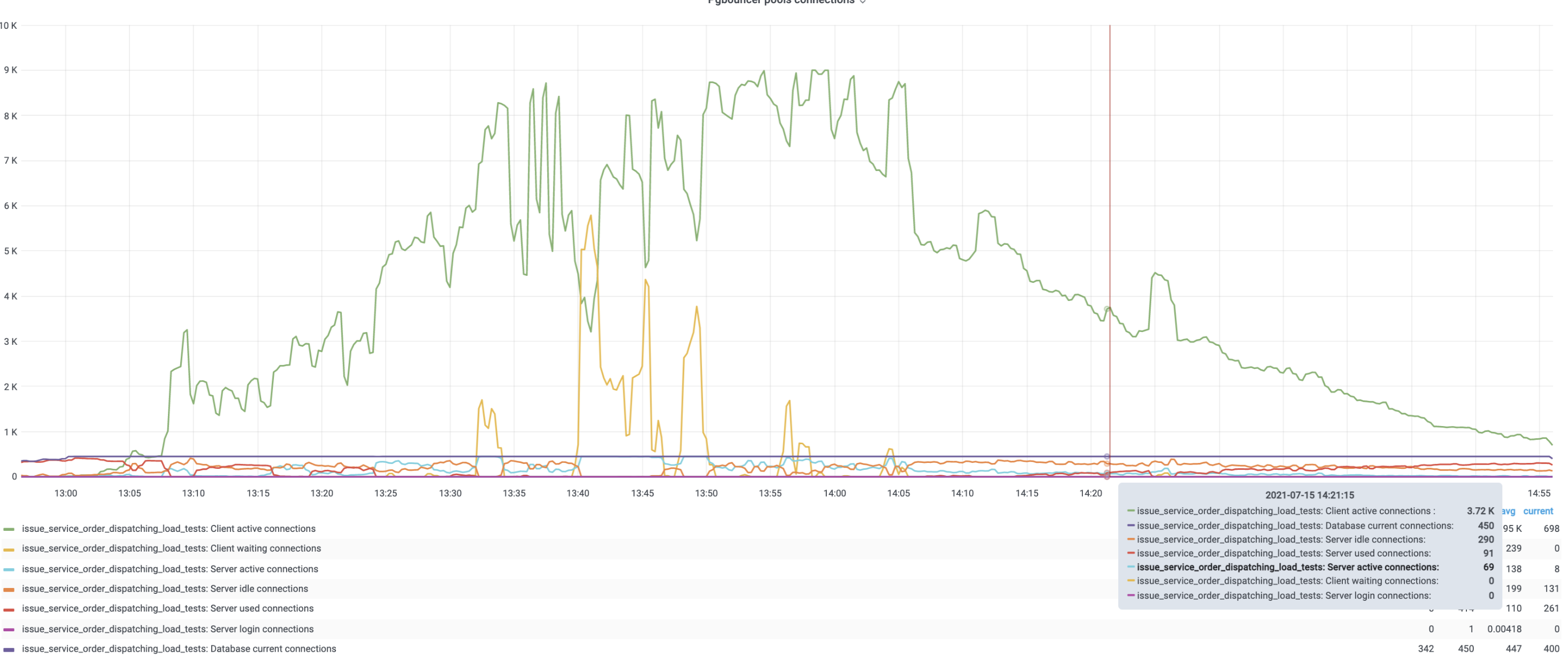
Too many clients start pilling up on PGBouncer slowing things down affecting the app performance.
The app is currently able to handle 5x the load ever had in production but things have to be improved in the future.
Things like cache and further query optimizations might minimize round-trips to the DB tend to improve the general performance but the DB will always be the limiting factor here.
And here we are, the present. How can we make things better?
The desired future
The problem faced now its not about the language, so changing to Go or insert-your-fancy-technology-here wont solve the problem because it lies in the approach itself, remember the actor model? Well if the app didnt have to search things in the DB for every single job the problem would be avoided. How would that look like?
While migrating the application to the new approach, we had the opportunity to write a load-test app in elixir to understand better what are the pain points of using this tool, unfortunately I believe I wont have time to work on it but I know that would be pretty viable. The solution using GenServers is not perfect, though, it eliminates the round-trips to the DB but it might increase the memory consumption considerably. Another point is that the state would have to be pretty well managed to avoid unexpected bugs or problems but I still believe that’s a best solution compared to the Sidekiq recursive approach.
Conclusion
As Developers, Software engineers or whatever name you might use, we like to learn new languages and sometimes to use newest one, however just changing the language by itself doesnt improve things magically.
Most of apps that I worked on so far are heavily limited by external calls (HTTP, DB, Network) so in most of the cases if you are running a web app, it doesnt matter much how fast the language is, if you are doing things right it should be enough. Not everybody is the Google. For me, it matters way more features like how easy to maintain, onboard new members, how fast to deploy, and run specs allowing cycles to run faster and that doesnt depend on the language itself.
So before considering moving to other language and wasting time and money, try to improve the project you are working on, MEASURE, observe your system, know the weeknesses and the strenghts, try to talk to other people and share your ideas/problems with others. If you want to take one thing from this post just consider applying the Scientific Method that according to Sedgewick & Wayne is:
- “Observe some feature of the natural world, generally with precise measurements;
- Hypothesize a model that is consistent with the observations;
- Predict events using the hypothesis;
- Verify the preditions by making further observations;
- Validate by repeating until the hypothesis and observations agree; “
And iterate over it!
Once one apply this, the difference will be noticiable, that I can tell you for sure, these things are game changers, apply it and be happy. I strongly believe that programming languages are tools in our utility belt and even though we as developers we have our preferences (me included, I ♡ Ruby) we should always be accontable to use the best tool to the job.
Special Thanks
I’m really happy I’ve contribuited to a such nice project and happy to have worked with my team mates. Thanks for your understanding and patience along the way. I’m really proud on what we together as a team have done :)
References
- https://algs4.cs.princeton.edu/home/
- https://rob-bell.net/2009/06/a-beginners-guide-to-big-o-notation
Cover Photo by Chris Lawton on Unsplash